
Introduction
Philippe le disait dans son article précédent, chez Liksi on aime les chatbots. Et même si on aime Dialogflow, on se dit qu’avoir une solution de repli en cas de changement tarifaire de Google peut être utile (cf Google Maps récemment). Il ne s’agit néanmoins pas seulement d’une problématique tarifaire. Comme je l’évoquais dans l’article sur le BreizhCamp 2018, il n’est parfois pas possible de fournir ses données à un service tiers comme Dialogflow. Du coup, on s’est penché sur des projets qui permettent de faire ça nous même et on a trouvé plusieurs solutions, par exemple Rasa avec sa solution rasa_nlu.
L’objet de cet article est de présenter ce qu’est un moteur NLP (Natural Language Processing) et d’expliquer une partie de son fonctionnement en codant un extracteur de thème de textes (ou d’intent pour un chatbot) sous python. Une partie du code sera donnée dans l’article. La totalité du code permettant de comprendre les étapes principales sans rentrer dans les détails théoriques est disponible sur le repository github de l’article.
Moteur NLP
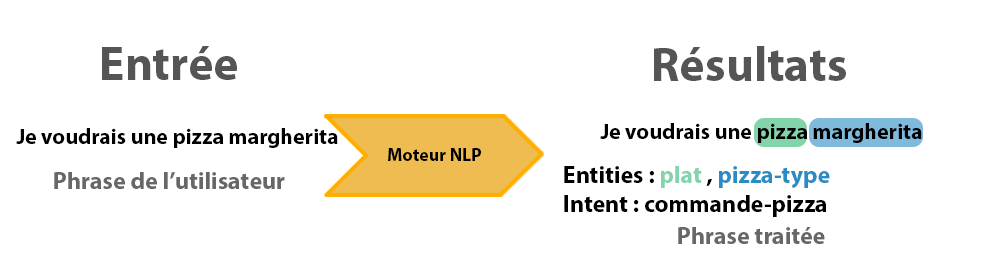
Un chatbot (aussi appelé agent conversationnel) permet de dialoguer avec un utilisateur. Par exemple, on peut lui demander des informations manquantes par rapport à un besoin (le nom de la pizza que l’utilisateur souhaite manger), ou tout simplement effectuer des actions et répondre à l’utilisateur. Pour opérer cette magie noire, on peut choisir d’inclure un moteur NLP.
Un moteur NLP a deux fonctions principales :
- Retrouver l’action/le thème associé à une phrase (intent en anglais)
- Retrouver les paramètres contenus dans cette phrase (entities en anglais)
Rasa est un moteur NLP et il permet de définir des pipelines de machine learning pour réaliser cela. Nous allons ci-dessous faire une présentation haut niveau des différents composants d’une chaîne d’extraction d’intents disponibles dans Rasa. L’évaluation en détail de ceux-ci n’est pas possible dans la solution Rasa, on présentera ainsi une méthode permettant cela en prenant l’exemple de la classification d’une partie du corpus issue de 20 newsgroup.
C’est à dire retrouver le newsgroup associé à un texte parmi les catégories :
- sci.space
- sci.electronics
- comp.sys.mac.hardware
- comp.windows.x
- rec.sport.baseball
- rec.sport.hockey
On va utiliser scikit-learn pour récupérer les données liées à ces catégories :
categories = [
"sci.space",
"sci.electronics",
"comp.sys.mac.hardware",
"comp.windows.x",
"rec.sport.baseball",
"rec.sport.hockey",
];
newsData = fetch_20newsgroups(
(subset = "train"),
(categories = categories),
(remove = ("headers", "footers", "quotes"))
);
Extraire des intents
Les algorithmes de classification fonctionnent souvent de la même façon : on place en entrée un vecteur de caractéristiques représentant nos données (notre phrase dans le cas NLP) et on obtient en sortie la probabilité que ces données appartiennent à tel ou tel autre catégorie (les intents dont on parlait précédemment).
[/et_pb_text][/et_pb_column][et_pb_column type=“1_2” _builder_version=“3.25.2”][et_pb_text _builder_version=“3.25.2”]
Pour obtenir de bons résultats, il faut se pencher sur la façon de construire ces vecteurs (étape Featurization dans l’image ci-dessous). Deux méthodes seront présentées dans la suite de l’article (CountVectorizer ou Bag Of Words et Word2Vec).
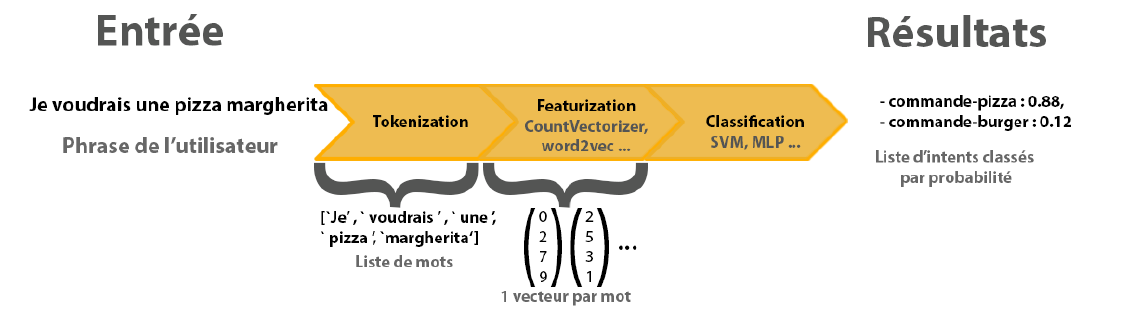
Pipeline d'extraction d'intents
Vectorisation des phrases
La première étape des méthodes de vectorisation utilisées dans la suite de l’article est de construire un vocabulaire à partir d’un corpus de phrases. On indexe chaque mot présent au minimum n fois dans les documents.
On peut décider de ne pas tenir compte de certains mots comme les déterminants qui n’apportent pas grand chose au sens d’une phrase.
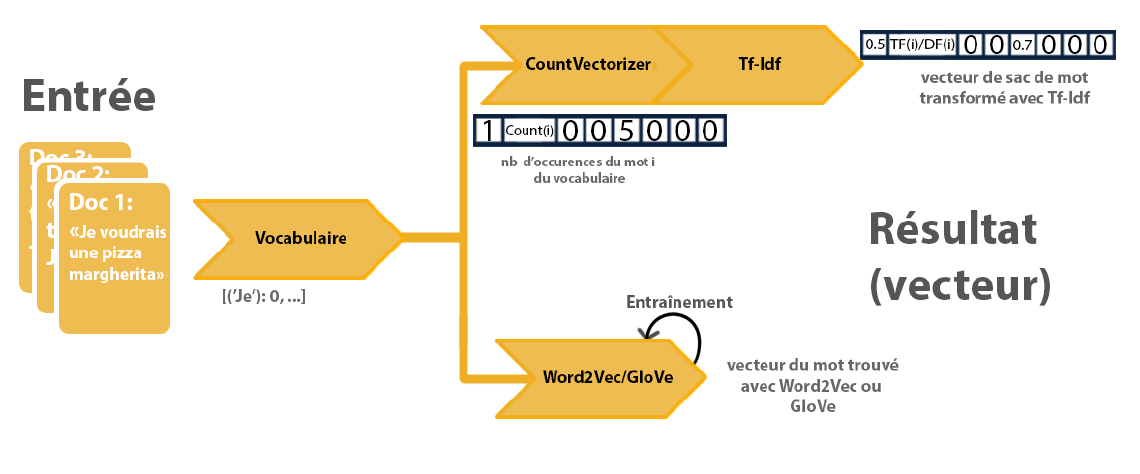
La préparation des données pour former nos vecteurs peut se faire de la façon suivante :
#nlp va permettre de tokenizer et de récupérer un modèle de vecteurs pré-entraînés (GloVe, équivalent à Word2Vec)
nlp = spacy.load('en', disable = ['tagger','parser','ner','textcat'])
xFull = newsData.data
target_names = newsData.target_names
y = newsData.target
xTokenized = []
xGloVe = []
for news in newsData.data:
doc = nlp(unicode(news))
#Récupération des vecteurs associés aux phrases (moyenne des vecteurs des mots de chaque phrase)
xGloVe.append(doc.vector)
#Récupération des phrases tokenizés (coupés)
xTokenized.append([token.text for token in iter(doc)])
- xFull permettra d’entraîner une pipeline basée sur CountVectorizer qui prendra en entrée un ensemble de phrases
- xTokenized permettra d’entrainer notre propre modèle word2Vec
- xGloVe utilisera les vecteurs pré-entraîné issus de spaCy (et de Common Crawl)
Bag Of Words
La solution appelée Bag Of Words, ou CountVectorizer consiste à associer à chaque phrase un vecteur de la taille du vocabulaire avec le nombre d’occurrence du mot i à l’index i. À cela on peut appliquer une transformation comme TF-IDF pour obtenir le vecteur final associé à la phrase. Un problème qui apparaît avec cette méthode est la perte d’informations liées à l’ordre d’apparition des mots, par exemple les 2 phrases “Je voudrais une pizza margherita” et “Pizza voudrais je margherita” seront représentés de la même façon.
Pour pallier ce problème, on peut utiliser des séquences de plusieurs mots plutôt que des mots uniques, c’est ce qu’on appelle des N-grammes (unigramme ou bigramme pour 1 et 2 mots). Des tests ont été faits sur le dataset 20 news group et la différence de score (91% pour des séquences de 1 mot contre 92% pour des séquences de 2) ne semble pas significative. Dans les fait, on utilise le CountVectorizer de la librairie scikit-learn qui apparaît en premier dans la pipeline scikit-learn
pipelineFull = Pipeline([
("vect", CountVectorizer()),
("tfidf", TfidfTransformer()),
("clf", LinearSVC()),
]);
Word2Vec
Comme expliqué précédemment, la solution Bag Of Words, en ce concentrant sur l’occurrence des mots sans prendre en compte leurs environnements, semble abstraire une partie des informations contenues dans les phrases. Afin d’essayer de construire des vecteurs plus pertinents de mots, Mikolov et al. proposent d’entraîner un réseau de neurones composé d’une couche d’entrée, d’une cachée et d’une couche de sortie sans fonction d’activation. C’est le modèle Word2Vec. L’objectif est d’entraîner le réseau de neurones d’une des deux façons suivantes :
-
Modèle SKIP-gram : L’objectif du réseau est de prédire p(C(contexte)|m(mot) le contexte en considérant un mot. C’est à dire les mots entourant le mot considéré en entrée dans une fenêtre donnée. Les vecteurs des mots seront pris comme les lignes de la matrices de poids de la couche cachée. L’entraînement sera fait en minimisant la somme des erreurs par rapport à chaque mot du contexte de sortie. (voir la figure suivante pour comprendre en image)
-
Modèle Continous bag of word (CBOW) L’objectif du réseau est de prédire p(m(mot)|C(Contexte)) le mot en considérant un contexte particulier. Les vecteurs des mots seront pris comme les lignes de la matrices de poids de la couche de sortie. La sortie de la couche cachée sera prise comme la moyenne des sorties pour chaque mot du contexte. L’entraînement sera fait en minimisant l’erreur de prédiction par rapport au mot à prédire.
Les réseaux de neurones obtenus ne sont pas utilisés en tant que tels, on s’intéresse à récupérer les poids des matrices associées aux différentes couches pour construire les vecteurs des mots. Afin d’expliquer l’idée derrière ce choix, on présente le modèle SKIP-gram. Pour cet exemple, on se place dans une simplification en considérant un vocabulaire de 8 mots uniquement et en prenant une taille de contexte d’un mot pour une fenêtre de taille 2 (si on en avait plusieurs mot dans le contexte, on moyennerait le résultat de la couche cachée).
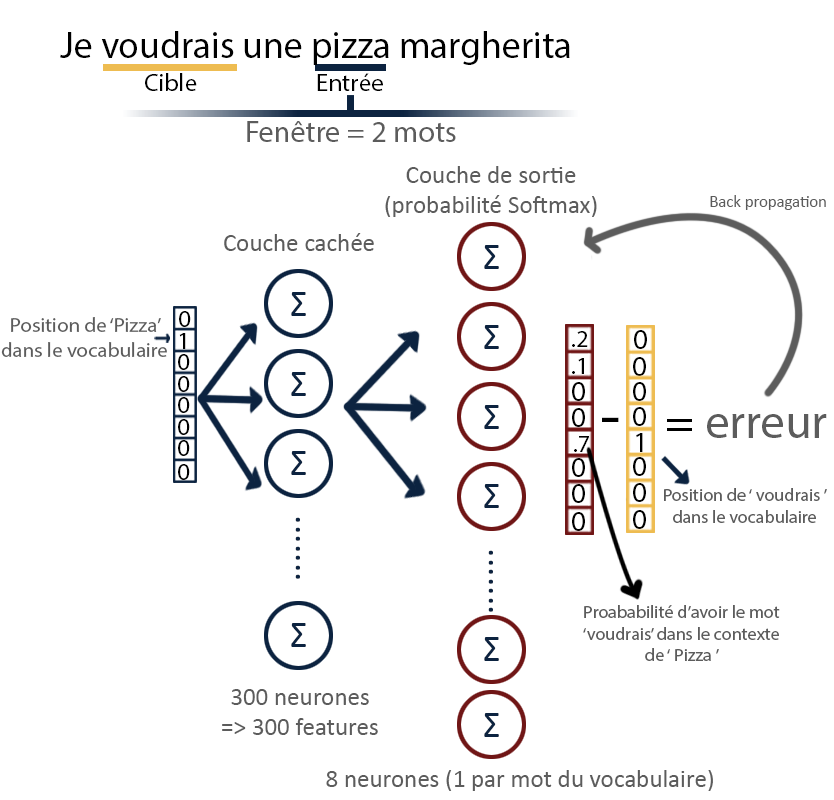
Schéma de fonctionnement global d'un modèle SKIP-gram word2Vec
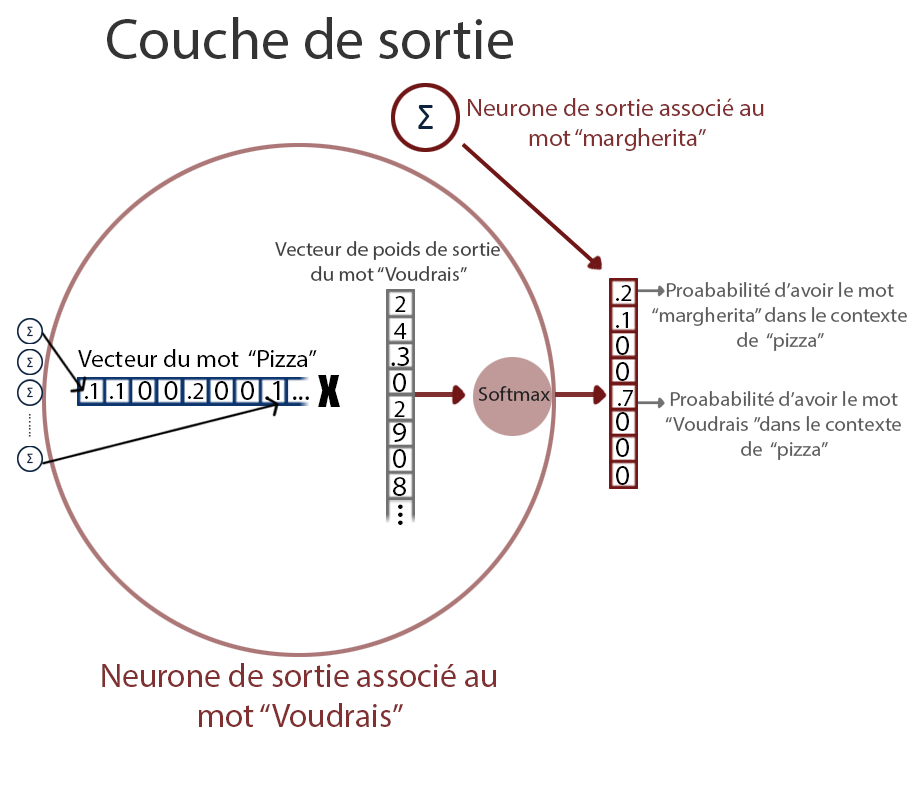
Action de la couche de sortie
Si l’on se concentre sur la sortie de la couche cachée, on remarque que la sortie de chaque neurone n’est autre que le poids associé au mot du vocabulaire par le neurone concerné. La couche cachée agit alors comme une table de correspondance. Comme le réseau est totalement connecté, chaque neurone de la couche de sortie reçoit donc les poids associés au mot d’entrée par chaque neurones, c’est ce qu’on prend pour le vecteur du mot. Il le multiplie alors par vecteur de poids de sortie associé à son propre mot et applique la fonction Softmax pour obtenir la probabilité d’avoir ce mot dans le contexte avant de calculer l’erreur par rapport à la cible et d’effectuer l’entraînement du réseau.
La question est alors de savoir pourquoi ce choix de vecteur peut donner de bons résultats. L’idée est que si deux mots ont un contexte identique, la sortie du réseau de neurones prédisant le contexte pour ces deux mots devraient être quasi identique. L’une des solutions pour obtenir cela est d’avoir pour les deux mots des vecteurs très similaires.
On utilise Gensim pour créer notre propre modèle Word2Vec, la théorie est un peu complexe mais cela peut se faire en une ligne python :
modelWord2Vec = Word2Vec(xTokenizedTrain, size=100, window=5, min_count=5, sg=1)
- size : correspond aux nombre de features que l’on veut (donc aux nombres de neurones dans la couche cachée
- window : la fenêtre de selection des mots dans le contexte
- min_count : le nombre minimum d’apparition nécessaire d’un mot pour le considéré dans le vocabulaire
- sg = 1 permet de selectionner le modèle skip-gram
On peut tester notre modèle en lui demandant les mots ayant les vecteurs les plus proches de “space” dans notre modèle :
print(modelWord2Vec.wv.most_similar("space"))
>[(u'research', 0.8191206455230713),
(u'station', 0.8022928833961487),
(u'shuttle', 0.7992041707038879),
(u'lunar', 0.7868685126304626),
(u'development', 0.783505916595459),
(u'launch', 0.7833254337310791),
(u'technical', 0.7800613641738892),
(u'various', 0.7703723311424255),
(u'exploration', 0.7679097056388855),
(u'technology', 0.7610211372375488)]
Les mots qui en ressortent ont l’air plutôt en accord avec ce qu’on pourrait attendre.
Classification et évaluation des pipelines
Scikit-learn permet de définir des GridSearch afin de trouver les meilleurs paramètres en terme de performance des composants d’une pipeline. On peut par exemple lui demander d’optimiser Les rapports donnent les informations de précision et de rappel des différents classificateurs, on présente aussi les matrices de confusions associées.
Pour comprendre les différentes valeurs présentes, on peut se référer à ce schéma issu de la page wikipedia sur la précision et le rappel:
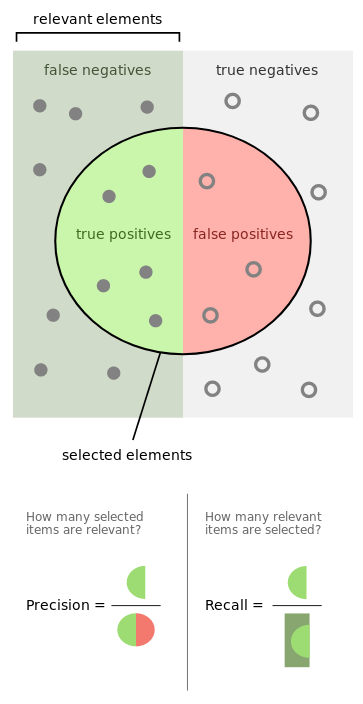
Définition des performances d'une méthode classification
Pour trouver ces valeurs pour nos classificateurs, on utilise la fonction classification_report de scikit-learn, qui donne en plus le score f1 (moyenne harmonique de la precision et du rappel(recall)), et le support : nombre d’exemples utilisés pour avoir ce score.
Résultats avec les vecteurs issus de CountVectorizer + TF-IDF
Scikit-learn permet de définir des GridSearch afin de trouver les meilleurs paramètres en terme de performance des composants d’une pipeline. On peut par exemple lui demander d’optimiser Les rapports donnent les informations de précision et de rappel des différents classificateurs, on présente aussi les matrices de confusions associées.
Pour comprendre les différentes valeurs présentes, on peut se référer à ce schéma issu de la page wikipedia sur la précision et le rappel:
y_true, y_predFull = yTest, gridSearchFull.predict(xFullTest)
print(classification_report(y_true, y_predFull))
>
precision recall f1-score support
0 0.85 0.84 0.84 172 #classe 0 : sci.space
1 0.92 0.98 0.94 167 #classe 1 : sci.electronics
2 0.80 0.91 0.85 170 #classe 2 : comp.sys.mac.hardware
3 0.96 0.85 0.90 195 #etc.
4 0.85 0.83 0.84 189
5 0.90 0.87 0.89 173
avg / total 0.88 0.88 0.88 1066
Résultats avec les vecteurs issus du modèle pré-entraînés
y_true, y_predGloVe = yTest, gridSearchGloVe.predict(xGloVeTest)
print(classification_report(y_true, y_predGloVe))
>
precision recall f1-score support
0 0.77 0.77 0.77 172
1 0.84 0.92 0.87 167
2 0.80 0.88 0.83 170
3 0.92 0.81 0.86 195
4 0.86 0.78 0.82 189
5 0.82 0.88 0.85 173
avg / total 0.84 0.83 0.83 1066
Résultats avec les vecteurs issus de notre modèle Word2Vec
y_true, y_predOwnWord2VecModel = yTest, gridSearchFull.predict(xOwnWord2VecModelTest)
print(classification_report(y_true, y_predOwnWord2VecModel))
>
precision recall f1-score support
0 0.56 0.62 0.59 172
1 0.69 0.90 0.78 167
2 0.52 0.57 0.54 170
3 0.67 0.59 0.63 195
4 0.63 0.28 0.39 189
5 0.56 0.71 0.62 173
avg / total 0.61 0.60 0.59 1066
-
Les pipelines utilisant la vectorisation Bag of Words et le modèle GloVe (équivalent à Word2Vec) pré-entraînés performent de façon quasi équivalente.
-
Ceux utilisant un modèle Word2Vec entraîné sur nos données performent moins bien : le nombre de données pour entraîner notre modèle n’est pas assez important
Conclusion
On observe qu’il n’est pas très difficile de créer son propre pipeline de machine learning pour extraire des thèmes / intents de phrases. On pourrait pousser l’évaluation à d’autres méthodes de vectorisation (Doc2Vec, extension de Word2Vec) / classificateur (comme des Perceptron multi-couche).
Pour implémenter nos deux pipelines d’extraction dans Rasa on pourrait définir un fichier de configuration comme cela pour le CountVectorizer:
[
{
"name": "tokenizer_spacy"
},
{
"name": "intent_featurizer_count_vectors"
},
{
"name": "intent_classifier_sklearn"
}
]
et ainsi pour le modèle GloVe issu de spaCy :
[
{
"name": "tokenizer_spacy"
},
{
"name": "intent_featurizer_spacy"
},
{
"name": "intent_classifier_sklearn"
}
]
Pour aller plus loin …
et comprendre les résultats du classificateur basé sur le modèle Bag Of Words
On utilise la bibliothèque eli5 qui permet de rentrer dans le fonctionnement des classificateurs basés sur des SVM (support vector machine). On récupère les étapes de vectorization et de classification de notre gridSearchFull et on affiche les poids associés aux différents mots les plus influents sur la classification dans telle ou telle catégorie :
vectorizer = gridSearchFull.best_estimator_.named_steps["vect"]
classifier = gridSearchFull.best_estimator_.named_steps["clf"]
eli5.show_weights(classifier, target_names=target_names, vec=vectorizer, top=20)
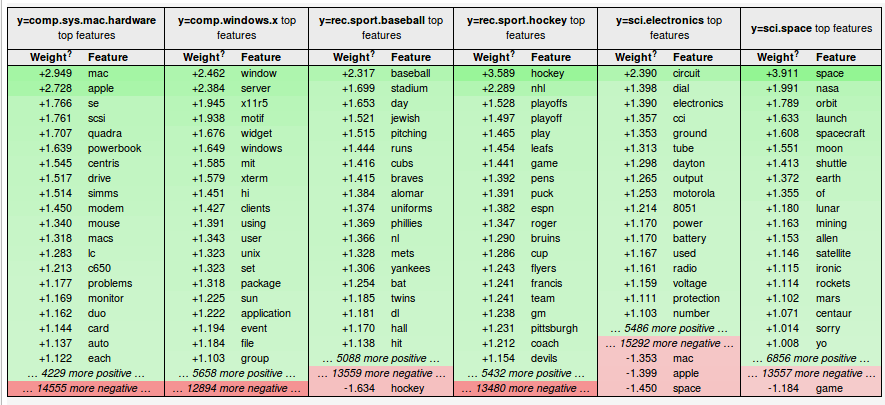
Poids associés aux différents mots dans chaque catégorie
Les mots “mac” et “apple” sont ceux qui influencent le plus la classification d’un article dans la classe comp.sys.mac.hardware, ce qui semble logique.
On peut aussi s’intéresser à voir la contribution de chaque mot dans un example de cette classe comp.sys.mac.hardware:

Influence de chaque mot d'un exemple dans la classification dans les 2 classes "comp.sys.mac.hardware" et "comp.windows.x"
On reviendra sûrement avec un deuxième article dans le même format pour parler de l’extraction d’entités, composant indispensable d’un moteur NLP.


