
Avec l’émergence des services de PaaS ou d’IaaS, l’écosystème IT est en grand chamboulement ces dernières décennies. Les bénéfices apportés par ces solutions séduisent de nombreuses entreprises pour réduire leur coût opérationnel et délivrer de la valeur au plus vite.
D’un point de vue purement technique, là où historiquement un service applicatif était un monolithe déployé sur une vm (ou un serveur bare-metal), l’actualité se trouve donc dans les architectures microservices déployées sur des orchestrateurs de conteneurs. Cette approche conceptuelle a plusieurs bénéfices:
- Lissage du déploiement avec le CD et de l’IaC,
- Pas de rupture de service avec du rolling upgrade
- Répartition de la charge avec du load balancing et l’instanciation de conteneur.
Cependant la mise en place de tels concepts possèdent des contraintes de développement lorsque le service doit maintenir un état partagé entre les différentes instances ou que les instances doivent discuter entre elles.
A travers cet article que nous vous proposons, nous verrons les points de blocages découlant de ces contraintes ainsi que les solutions qui peuvent être amenées.
Les données en mémoire
Qu’est-ce qu’un service stateless ?
On appelle service “stateless” un programme qui ne maintient pas d’état en mémoire pendant son exécution. Lorsque l’on se place dans un contexte multi-instance, avoir des services stateless est fondamental puisque les requêtes peuvent alors être traitées indifféremment par l’une ou l’autre des instances. Dans le cas contraire (avec des services stateful donc), une même requête pourrait avoir un résultat différent en fonction de l’instance qui l’exécute.
Qu’est-ce qui rend un service stateful ?
Souvent un service est stateful pour conserver des données entre deux transactions faites par un même utilisateur : c’est ce que l’on appelle des données de session et c’est un problème bien connu. Néanmoins, il y a d’autres cas où un service est stateful :
- si votre service met en cache des résultats
- si votre service initialise des données lors du démarrage, par exemple en appelant un service tiers pour initialiser une variable
- si votre service met à jour des données qui sont stockées en mémoire, par exemple pour calculer des statistiques
Si l’équipe de développement est peu expérimentée, il est assez fréquent que ces cas soient implémentés sans que l’équipe s’en aperçoive, et qu’un service censé être stateless ne le soit plus. Dans ce cas, le passage en multi-instances donnera lieu à des comportements qui semblent aléatoires. Le problème de multi-instances en mode stateful est résumé sur le schéma ci-dessous :
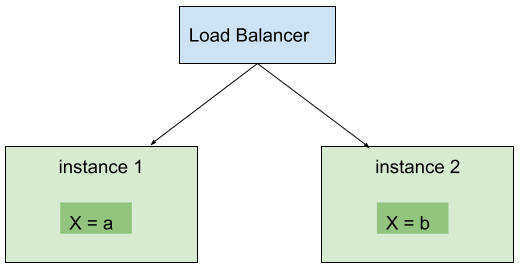
Sur ce schéma, il est évident que si vous envoyez une requête qui retourne la valeur de X, le résultat sera différent en fonction de l’instance qui traite la requête.
Comment remettre un service en mode stateless ?
Pour remettre un service dans le droit chemin, il n’y a pas d’autres solutions que de regarder le code en détail et faire la chasse aux services qui stockent des valeurs (qui ne sont pas des dépendances vers d’autres services ou des paramètres).
Cas du cache
Si votre service utilise un cache alors vous devrez transformer ce cache en cache partagé. Il existe plusieurs solutions pour faire cela et on peut distinguer deux modes : le cache “embedded” et le cache “standalone”.
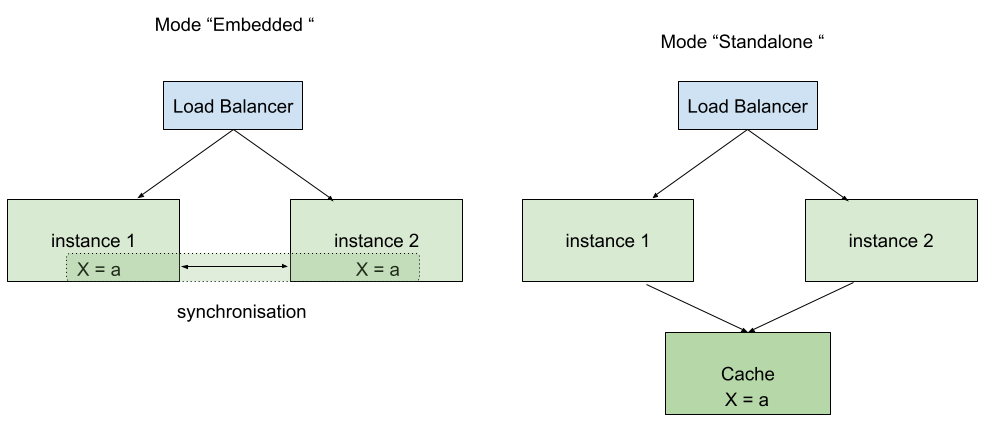
Cache “embedded”
Plusieurs technologies permettent de faire du cache partagé en ajoutant juste une dépendance dans votre application. Dans ce cas, des mécanismes de synchronisation vont permettre de garantir que les deux instances voient bien la même valeur pour X. Cela peut être soit avec de la réplication : les deux instances stockent la donnée et la synchronisation garantie la cohérence, soit avec de la distribution : dans ce cas, une seule instance possède la donnée et l’autre lui envoie des requêtes de lecture et/ou écriture.
Dans l’écosystème Java, les principales solutions de ce type sont Infinispan et Hazelcast.
Le principal avantage de ce mode est la simplicité de déploiement : il n’y a pas besoin d’ajouter de nouvelle brique d’infrastructure.
Cache “standalone”
En mode “standalone”, une nouvelle brique d’infrastructure est utilisée pour stocker et exposer les données du cache.
Hazelcast et Infinispan peuvent également être déployées en standalone mais des solutions comme Redis ou Memcached sont également très utilisées.
Les principaux avantages de ce mode est que l’on peut potentiellement mutualiser cette brique avec d’autres applications et que les données sont persistées même si toutes les instances de l’application s’arrêtent. En revanche, cela nécessite plus de travail pour le déploiement et la supervision (surtout que le service de cache est généralement déployé en haute-disponibilité).
Cas de l’initialisation
Dans le cas où la valeur stockée sert à initialiser le service, il faut savoir si toutes les instances vont toujours calculer la même valeur initiale ou pas. Si oui, et si le calcul n’est pas trop cher, on peut conserver la valeur en mémoire. Dans le cas contraire, l’utilisation d’un cache partagé est recommandée.
Par exemple, au lieu de faire un appel REST vers un service tiers au démarrage de manière systématique, vous pourrez ne le faire que si le résultat n’est pas dans le cache partagé. Ainsi, non seulement vous serez sûrs que tous les services utilisent bien la même valeur mais vous économiserez également des appels lorsqu’une nouvelle instance démarre pour rejoindre le cluster.
Cas des données “calculées”
Dans de rares cas, les services stockent des données en mémoire afin de conserver le résultat d’un calcul et cela n’aurait pas de sens d’assimiler ces données à du cache : par exemple s’il n’y a pas de notion d’expiration ni de “cache miss”. Pour ces cas, il faut utiliser une solution de stockage de données “classique”. Cela peut être :
- une base de données, dans le cas où les données doivent être persistées pour survivre à une extinction du cluster, ou si les notions de transaction et de cohérence forte des données sont importantes. Dans le cas général, c’est la solution la plus simple à mettre en place. On peut se reposer sur des solutions comme postgres, mariaDb ou mongoDb qui sont bien connues.
- une solution de type mémoire partagée pour les cas où la rapidité d’accès aux données est primordiale. Dans ce cas, on peut utiliser des solutions comme Hazelcast, Redis ou Memcached
Synchronisation de plusieurs instances
Il arrive fréquemment que l’on doive utiliser des mécanismes de synchronisation afin de garantir le bon comportement d’une application lorsque plusieurs requêtes sont exécutées simultanément. Dans le cas du multi-instances, il faut faire en sorte que deux threads puissent être synchronisés sur des instances différentes.
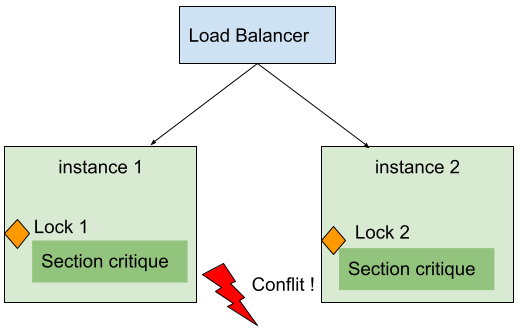
Pour cela, il faut utiliser un système externe, partagé, qui servira de point de synchronisation, comme indiqué sur le schéma ci-dessous :
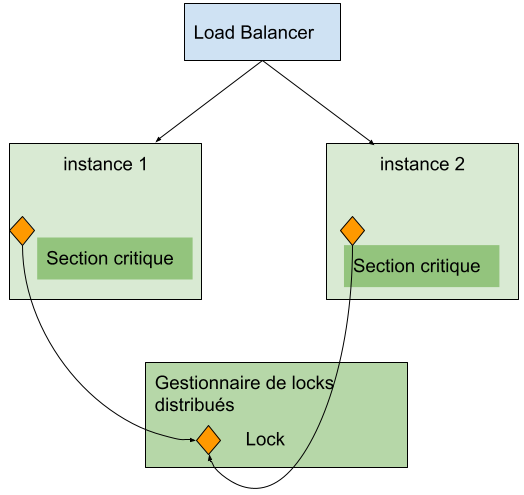
Les bases de données relationnelles utilisent nativement des locks pour garantir l’isolation des transactions et ces locks peuvent facilement être réutilisés pour synchroniser des threads applicatifs.
Par exemple, il est tout à fait possible de créer une table “Lock” et d’utiliser une requête de type “SELECT FOR UPDATE” pour prendre un lock sur cette table. Pour synchroniser deux thread, il suffit alors d’encapsuler les sections critiques dans une transaction SQL qui utilise cette requête.
La plupart des bases de données supportent différents modes de lock, il faut se référer à la documentation de chaque solution pour comprendre les limites et contraintes des différents modes. A titre d’exemple, voici la document pour Postgres https://www.postgresql.org/docs/14/explicit-locking.html et pour MongoDB https://docs.mongodb.com/manual/faq/concurrency/. Il faut également bien étudier le comportement du lock dans le cas où un nœud de la base de données tombe. Cette approche est souvent la plus simple à mettre en œuvre dans la mesure où elle repose sur une infrastructure qui existe la plupart du temps déjà.
Néanmoins, l’utilisation de la base de données comme point de synchronisation peut entraîner une surcharge de la base et des lenteurs en cas d’usage intensif des locks. Dans ce cas, il peut être intéressant d’envisager une solution comme Hazelcast pour n’utiliser que des locks en mémoire https://docs.hazelcast.com/imdg/4.2/data-structures/fencedlock. NB : le mécanisme de lock d’Hazelcast ne peut être utilisé que dans le mode “CP” qui pose certaines contraintes en production : https://docs.hazelcast.com/imdg/4.0/cp-subsystem/cp-subsystem
Réception de requêtes sur la mauvaise instance
Comme nous l’avons vu précédemment, le passage d’une application non clusterisée a clusterisé est bien plus facile lorsque le service est d’ores et déjà stateless. Cependant pour des services avec des composantes stateful fortes, il conviendra de bien identifier la ou les sections critiques du code.
Et lorsqu’on parle de clusterisation de services, certaines problématiques très liées à du stateful reviennent comme l’usage de websocket ou d’événementiel.
Si l’on prend le cas d’un service websocket qui est redondé, l’usage du websocket nous impose une composante stateful avec le maintien de la session et le maintien de la connexion. Et lorsqu’il y a déconnexion et reconnexion de l’utilisateur sur une autre instance, volontaire ou non, il n’est pas forcément souhaitable que l’utilisateur reprenne son processus à zéro.
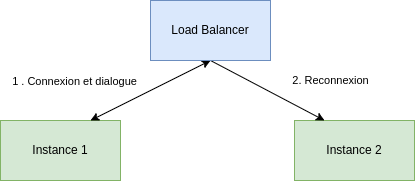
Dans ce cas, on visualise vite que la section critique concernée est la session de l’utilisateur. Il conviendra alors de synchroniser les sessions à l’aide d’un cache partagé entre les différentes instances(avec Hazelcast, Infinispan ou Redis par exemple). Ainsi par exemple, si l’utilisateur doit se reconnecter suite à un problème technique, il peut repartir sans impact sur ce qu’il faisait avant.
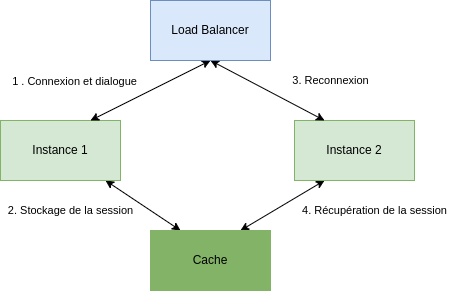
Le cas du polling est assez similaire. Alors que la première requête interrogera une instance et déclenchera une récupération ou un processus, l’utilisation du load balancer forcera les requêtes suivantes sur d’autres instances. Une approche naïve serait de laisser les instances du service faire le job sans se soucier des surcoûts d’appels ou des possibles collisions qui pourraient arriver. Une approche plus réaliste serait d’identifier les sections critiques et de les stocker dans le cache. Par exemple, dans le cas d’un polling sur une récupération d’une donnée, il pourrait être intéressant alors de stocker la donnée dans le cache dès lorsque celle-ci est disponible afin que toutes les instances puissent accéder à la donnée.
Un autre cas revenant souvent est l’usage de deux flux événementiels par un service, par exemple un service utilisant du websocket ainsi qu’un broker. Alors que l’utilisateur sera connecté à travers le websocket sur une instance, si un message arrive sur une autre instance, il sera nécessaire que ce message soit restitué à l’utilisateur.
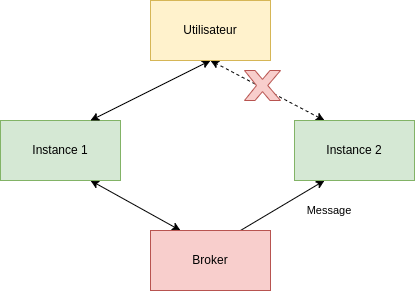
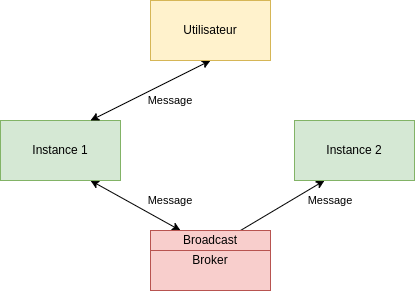
L’une des réponses qui peut être apportée est de pouvoir configurer son broker en Pub/Sub afin de broadcaster le message sur les différentes instances. Ainsi, toutes les instances recevront le même message et seule celle avec la connexion active sera chargée de le traiter.
Les tâches planifiées
Il est courant pour une application d’avoir des traitements planifiés, que ce soit pour lancer des traitements de cohérence, de nettoyage, etc.
Une implémentation naïve dans l’univers Spring-Boot se ferait de la manière suivante :
@Service
class SpringSchedulerImpl(
private val stockCheckService: StockCheckService,
) {
@Scheduled(cron = "0/20 * * * * ?")
fun scheduledStoreChecks() {
stockCheckService.checkStocks()
}
}
On a un service Spring qui définit une méthode scheduledStoreChecks() annotée par @Scheduled, qui permet à Spring de déclencher l’exécution automatiquement, ici configurée pour s’exécuter avec un CRON toutes les 20 secondes.
Comme dans les parties précédentes, nous allons avoir quelques problèmes lors du passage de notre application à plusieurs instances : nous ne voulons pas que la méthode s’exécute sur les trois instances. Une seule d’entre elles est à même de valider l’état d’un stock.
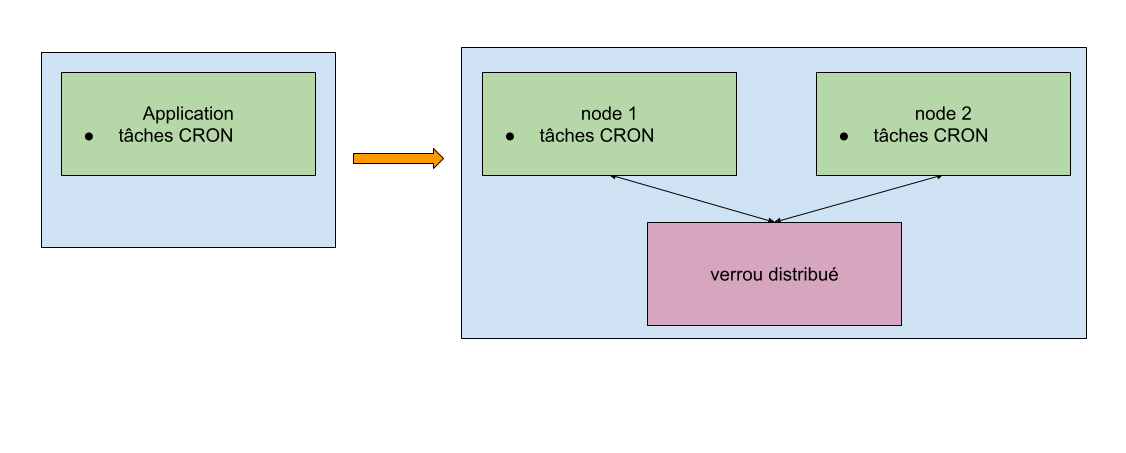
Afin de pallier ce problème, il y a plusieurs solutions disponibles. Nous utiliserons ici une librairie appelée ShedLock, qui va placer un lock distribué qui peut être stocké en base de données, dans un cache, etc.
Hazelcast faisant déjà partie de notre stack, nous allons l’utiliser pour stocker le lock distribué :
@Configuration
class ShedLockConfig {
@Bean
fun hzLockProvider(hazelcastInstance: HazelcastInstance): LockProvider {
return HazelcastLockProvider(hazelcastInstance)
}
}
Nous ajoutons une annotation @SchedulerLock à la méthode SpringSchedulerImpl.stockCheckService(), et le tour est joué !
@Service
class SpringSchedulerImpl(
private val stockCheckService: StockCheckService,
) {
@Scheduled(cron = "0/20 * * * * ?")
@SchedulerLock(name = "SpringSchedulerImpl_scheduleStoreChecks", lockAtLeastFor = "PT5S", lockAtMostFor = "PT19S")
fun scheduleStoreChecks() {
stockCheckService.checkStocks()
}
}
Il y a différents paramètres d’annotation configurables, voici l’explication des trois utilisés dans l’exemple:
- name : nom unique du lock, nécessaire à la librairie afin d’identifier les différents locks
- lockAtLeastFor & lockAtMostFor : durées décrites comme java.time.Duration.parse(CharSequence) – par exemple PT5H : 5 heures. Ce champ est utilisé notamment en cas de différence d’horloge des différentes instances, afin d’être sûr que la méthode reste bloquée pendant un laps de temps défini
Avec cette simple configuration, il est possible de déployer plusieurs instances de notre application sans se soucier du fait qu’une tâche ne se déclenche sur plus d’une instance.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row _builder_version=“4.0.6”][et_pb_column type=“4_4” _builder_version=“4.0.6”][et_pb_text _builder_version=“4.0.6” custom_margin="||-3px|||"]
En bref
| Piège | Contournement | Technologies |
|---|---|---|
| Données en cache local | Mise en place d’un cache partagé | Hazelcast, Infinispan, Memcached, Redis, … |
| Données calculées à l’init du service | Transformer le code pour se ramener au cas du cache | |
| Données stockées localement | Stockage en base de données ou dans une mémoire partagée | Postgres, MongoDB, … Hazelcast |
| Utilisation des sessions websockets | Mise en cache des sessions | Hazelcast, Infinispan, Memcached, Redis, … |
| Deux flux evenementiels | Broadcast les messages sur les subscribers des évenements | Pub/Sub, Broker |
| Synchronisation de threads | Utilisation des mécanismes de lock des bases de données ou locks “in-memory” | Postgres, MongoDB, … Hazelcast |
| Tâches planifiées | utilisation d’un verrou partagé | Shedlock, QUartzScheduler |
Conclusion
Changer d’architecture pour une application, en passant de une à plusieurs instances, ajoute de la complexité à un projet. Cependant, il existe aujourd’hui des solutions permettant d’en régler une grande partie comme énoncées dans cet article, notamment au niveau de la gestion d’un cache partagé, des tâches planifiées ou d’un changement d’interface.
Code source
Un projet reprenant plusieurs problématiques remontées est disponible ici : https://gitlab.com/corentin.normand/spring-boot-app-clustering


