
Du 20 au 22 mars 2019 s’est tenu le BreizhCamp dans les universités de Rennes. La conférence à l’ouest permet de rassembler 600 développeurs et développeuses de nombreuses communautés autour d’une grande diversité de thèmes. Cette année, dans l’ensemble, pas de grosses révolutions dans les sujets (comme l’ont pu l’être Docker ou Kubernetes il y a quelques années de cela) mais de la consolidation, du REX, des best-practices, de l’outillage ou encore de la méthode.
Pour l’occasion, nous vous avons concocté un résumé des quelques conférences qui nous ont marquées… so “Who we gonna pick ?”

Scuttlebutt - Construire un Facebook décentralisé
Mercredi 13h30 - 14h25

Mercredi après-midi Antoine Cailly a présenté Scuttlebutt, un protocole simple et peer-to-peer conçu pour créer un réseau social décentralisé. Dans ce protocole, chaque utilisateur a une paire de clé asymétriques et peut communiquer avec tous les autres nœuds dès lors qu’il en connaît l’adresse IP et la clé publique. Grâce à la cryptographie asymétrique, tous les messages sont signés et chiffrés.
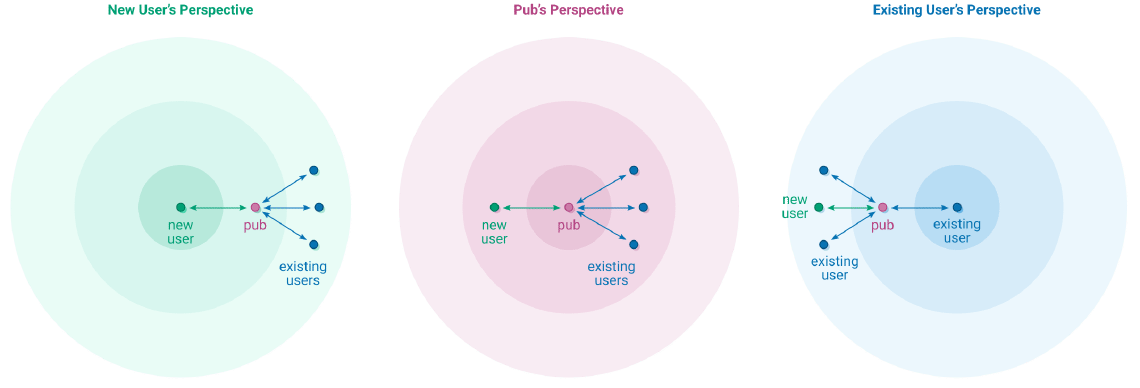
Dans ce réseau, chaque nœud héberge les données (messages envoyés et reçus) de l’utilisateur et une réplique des données des contacts (rang 1) ainsi que des contacts de ses contacts (rang 2). Ce mécanisme permet d’une part d’avoir de la réplication de données et d’autre part de “rencontrer” d’autres utilisateurs.
De plus afin de socialiser et trouver de nouveaux pairs, les pubs sont des nœuds particuliers qui fonctionnent comme des miroirs des données des “amis” connectés à lui. Un pub a une adresse IP statique et une clé publique accessibles sur internet et permet donc à tout un chacun de rencontrer des utilisateurs hors de son propre réseau.
De la même manière que dans les blockchains, la perte des clés privées est un problème majeur puisque c’est ce qui permet à un utilisateur de s’identifier sur le réseau. Un nouveau projet, Dark Crystal, tente de résoudre ce problème en utilisant l’algorithme de cryptographie Shamir’s Secret Sharing. Cet algorithme permet de diviser le secret en différentes parties qui sont données à chaque participant (clé partagée). Pour reconstruire le secret, il suffit de réunir un sous-ensemble de ces parties.
Contrairement à Facebook ou autres réseaux centralisés, Scuttlebutt n’est qu’un protocole d’échange peer-to-peer fait pour que des applications proposent des services par dessus.
Patchwork, le client le plus utilisé de Scuttlebutt, propose une interface intuitive similaire à Twitter mais il existe d’autres applications, comme par exemple un jeu d’échecs où les mouvements sont en fait des messages Scuttlebutt.
L’inconvénient majeur reste peut être que les identités ne sont pas simples à retenir… Suivez-moi sur @sTb+k9WS4c80mbKhIluTr7t3sHNVb+ySvMgtK3XHmng=.ed25519 ! 🙂

Florencia Alvarez Etcheverry, Tristan Denmat
Références : Présentation, Guide sur Scuttlebutt, Site de Scuttlebutt
Comment j’ai hacké ma prise électrique
Mercredi 14h35 - 15h30
Sous couvert d’un nom fort peu attractif, Florent Vuillemin nous parle de la façon avec laquelle il est parvenu à prendre le contrôle de sa prise électrique intelligente, achetée en Chine pour une vingtaine d’euros.
Première étape : connecter la prise intelligente à son pc avant de la connecter à internet, avant qu’elle puisse mettre à jour son firmware (oui oui, demain vos prises électriques auront besoin de se mettre à jour elles aussi). Un netstat lui annonce que la prise en question exposait plusieurs ports réseau : les 22, 80, 443 et 8080. Le port 22 étant le port par défaut d’un serveur SSH, nous sommes en droit de nous demander pourquoi il existe un serveur SSH sur une prise électrique. Question restant sans véritable réponse : peut être que le constructeur souhaite pouvoir y accéder à distance dans un souci de maintenance ? Dans notre cas, il nous permettra d’accéder à des informations plutôt intéressantes.
Viennent ensuite les ports HTTP. Ceux-ci sont exposés afin de mettre à jour le firmware de la prise, mais également de recevoir des informations des serveurs de l’entreprise les produisant. Cependant, l’action se déroulant en 2015, le chiffrement des données lors de flux HTTPS n’était visiblement pas autant la norme qu’aujourd’hui. Résultat, lors du branchement de la prise à l’ordinateur, celle-ci exécute une requête HTTP en clair sur les serveurs de contrôle du constructeur. Florent se retrouve donc avec d’un côté une IP publique du serveur de contrôle, et de l’autre le firmware de l’application, qu’il a pu disséquer avec des outils qui m’étaient jusque là complètement complètement inconnus !
Une fois le filesystem du firmware décompressé, il a pu accéder à quelques fichiers plutôt intéressants : des binaires de production, de test, et surtout une clé SSH publique ! Après maintes manoeuvres, il parvient à la remplacer par une clé publique générée par ses soins, et à recompresser le filesystem dans le firmware.
Il parvient ensuite à faire pointer la prise vers un serveur web local, qui expose le firmware modifié, et tadaa ! Florent peut se connecter en SSH sur sa prise. Tous les binaires du firmware qui n’étaient pas exécutables sur son PC pour cause d’une trop grande différence de matériel peuvent donc s’exécuter sur la prise. Et là surprise (encore, me direz-vous) ! Les binaires en question loguent une quantité importante d’informations sur la sortie standard. Quelqu’un de malin pourrait donc se servir des noms de fonction non offusquées et des numéros de lignes apparaissant de cette façon pour comprendre le code décompilé des binaires. Ce qu’a bien évidemment fait notre conférencier ; il a ainsi pu retrouver encore plus d’informations intéressantes, comme par exemple une clé d’API google maps, qui n’était même pas utilisée par l’application, des clés d’authentification, soit autant d’informations qui n’avaient rien à faire écrites en dur dans le code.
Florent n’est pas allé beaucoup plus loin, l’étape logique suivante étant d’essayer de dialoguer avec le serveur de contrôle en utilisant les informations gagnées précédemment. Mais cela rendait la chose beaucoup plus dangereuse, et ne valant pas forcément le coup.
Une chose que j’ai retenu est une citation très sympathique : “The S in IoT Stands for Security”. Si le constructeur avait utilisé des connections HTTPS pour tous leurs appels, à commencer par la récupération du firmware, rien de tout cela n’aurait été possible.
Corentin Normand
“Numérique et environnement” ou “On aurait pu sauver les abeilles, on a préféré sortir un nouvel iPhone”
Jeudi 16h00 - 16h55
Jeudi après-midi, Sébastien Brault, Software iOS developer, “identity and security specialist” à Orange se présente devant nous pour une conférence qui sort des classiques présentations techniques. Cette fois, on va parler environnement… et on va en parler sérieusement.
L’environnement c’est sans doute le plus grand des défis de notre époque. Et pendant un peu moins d’une heure, on nous expose l’impact du numérique sur l’environnement. On a tous lu ou entendu des phrases chocs du type “Une recherche sur Google correspond à 1 ampoule allumée pendant une heure”, mais ici, Sébastien Brault nous expose en détail les observations et conclusions d’un rapport du Think Tank “The Shift Project”.
Et si l’on n’est pas réfractaire à l’abondance de graphiques et autres statistiques, force est de constater que le message apporté par le conférencier est amené avec conviction et arguments.
Sur le fond, on y apprend que le numérique dans son ensemble (production, stockage, données, recyclage etc.) a un impact qui croît… et qui croît de façon exponentielle. On pourrait penser, comme souvent en occident, que nous sommes des bons élèves, du moins pas les pires… Mais non. Notre responsabilité dans les émissions de GES (gaz à effet de serre) est majeure et, selon les prévisions du Think Tank le restera à l’horizon 2020.
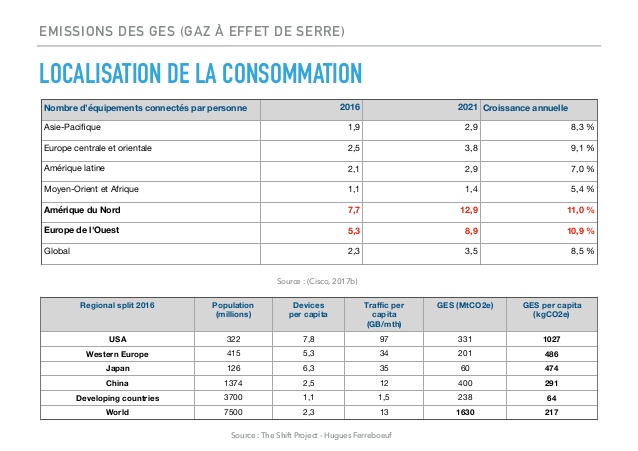
Sources : slides
Alors dans cette situation, que faire ? C’est ce que Sébastien Brault nous présente dans une seconde partie: “La sobriété comme principe d’action”. Consommer moins, mieux. Produire moins, mieux. Raisonner sa consommation et l’utilisation du numérique, tels sont les principes d’actions mis en avant.
Et puis la conférence termine en ouvrant sur le sujet du réchauffement climatique. Comment endiguer l’accélération brutale de l’accroissement des températures ? Vers combien de degrés allons-nous ? 1,5 ? 2 ? 3 ? Plus encore ? La bataille semble déjà perdue. Notre génération devrait émettre 6x moins de CO2 que la génération précédente…

Sources : slides

Sources : slides
Reste à limiter les conséquences et nous organiser pour la suite. Changer radicalement nos modes de vie est nécessaire mais serait-ce accepté par la population ? La question reste entière.
Pour finir, on balaye les conséquences de notre inaction sur la planète au travers d’un scénario probable (3,5°C) puis on termine par l’évocation du rapport Meadows… bref, on nous avait prévenu.

Sources : slides
On sort de cette conférence groggy, un peu désespéré il est vrai mais riche d’informations concrètes qui nous aideront surement à changer nos pratiques.
Références : Présentation
The CI as a partner for test improvement suggestions
Vendredi 10h30 - 11h25
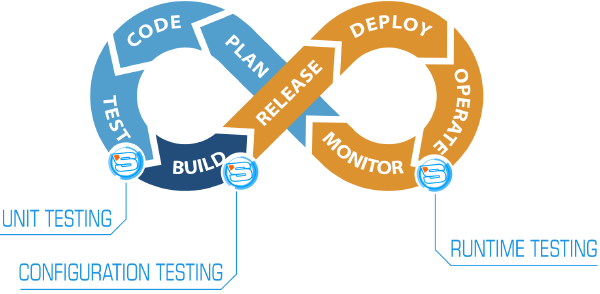
Vendredi matin, Caroline Landry est venue parler de STAMP (Software Testing AMPlification), un projet européen pour l’amplification de tests sur toute la chaîne de CI. STAMP a pour but de développer des outils qui augmentent la couverture et l’efficacité des tests automatiques en s’appuyant sur ceux existant.
Au programme d’aujourd’hui, focus sur les deux outils pour améliorer les tests unitaires.
Sources : Site du projet STAMP
Le premier, baptisé Descartes, permet de détecter des méthodes pseudo-testées en faisant des tests de mutation extrême (extrem mutation) : il remplace le corps des méthodes par des déclarations de retour (return), et vérifie que les tests échouent. Si ce n’est pas le cas, c’est qu’aucune assertion n’est faite sur la sortie de la méthode, et donc qu’elle n’est pas véritablement testée.
Le second outil, DSpot, vise à augmenter la couverture de test en amplifiant le corpus existant. En se basant sur les tests déjà écrits, il en génère de nouveaux en appliquant quelques opérations simples : suppression d’assertions, rejeu d’autres.
Ces deux outils ne concernent que les tests unitaires, mais le projet STAMP développe des outils qui s’intègrent sur toute la chaîne de création d’une application, du dev aux opérations.
Thomas François
Références : Site du projet STAMP, GitHub de Descartes, GitHub de DSpot
“Bogged down in the slime, Busters ? your python code can run fast !”
Vendredi 10h30 - 11h25
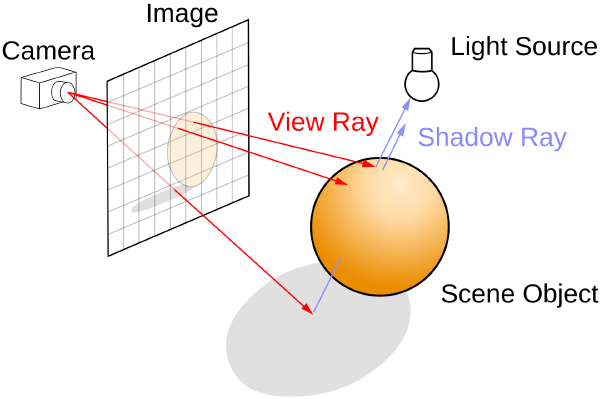
Vendredi matin, Pierre Rust, architecte logiciel à Orange, a présenté la façon avec laquelle il a procédé afin d’améliorer les performances au niveau d’un code Python. Il a développé une solution qui permet le ray tracing qui est une technique de calcul optique lourde par ordinateur.
Cette technique consiste à simuler le parcours inverse de la lumière.
[/et_pb_text][/et_pb_column][/et_pb_row][et_pb_row _builder_version=“3.25.2”][et_pb_column type=“4_4” _builder_version=“3.25.2”][et_pb_image src=“http://www.liksi.tech/wp-content/uploads/2019/07/Ray_trace_diagram.svg_.png” align=“center” _builder_version=“3.25.2” height=“347px”][/et_pb_image][et_pb_text _builder_version=“3.25.2”]
Sources : Site du projet STAMP
Bien que python soit considéré comme l’un des langages de programmation les plus lents, Pierre a réussi, en utilisant différentes techniques, à améliorer les performances de cette application. Afin de réussir à développer une application performante, cinq étapes doivent être faites:
- Réussir à développer le programme qui permet d’avoir les bons résultats.
- Tester le code de l’application afin de vérifier les résultats de ce dernier.
- Profiler l’application afin de repérer les bouts de codes qui doivent être optimisés.
- Optimiser le code.
- Répéter à partir de la deuxième étape.
Après la mise en place de la première version de l’application, le code python a donné des résultats décevants en matière de performances. Après l’étape de test, deux outils de profiling ont été adaptés:
- cProfile : permet un profiling déterministe des programmes Python. Ce profiler retourne des statistiques qui décrivent le nombre et la durée d’exécution de différentes parties du programme exécuté.
- VMProf : est une plateforme qui permet de comprendre et résoudre les problèmes de performance au niveau du code.
Après la détection des anomalies de performances, différentes suggestions que je vais lister ont été mises en œuvre :
- On commence tout d’abord par une amélioration algorithmique: une première approche adaptée consiste à utiliser une KD tree. C’est une structure de données de partition de l’espace permettant le stockage des points ce qui permet une recherche plus rapide (recherche par plage …).
- On vient ensuite effectuer un benchmark entre numpy, tuple, Vector3 ; en utilisant Pytest avec pytest benchmark, les différentes solutions de listes et tableaux ont été comparées. Après la comparaison effectuée, numpy avait les pires résultats et les tuples avaient les meilleurs. En effet les tableaux numpy sont personnalisés pour des calculs scientifiques avec des tailles de matrices importantes, alors que dans ce cas les tests sont basés sur des matrices de petite taille. L’utilisation de la bonne structure de données est une étape très importante lors du développement. En effet le choix se base en fonction du nombre maximal des données, les traitements à effectuer….
- L’utilisation de Cython: Cette étape a donné des résultats inattendus. Après cette étape, les performances de la nouvelle solution ont été améliorées 40 fois!. Cython permet la transformation du code vers un C/C++ optimisé. Il permet un gain de performances qui peut aller jusqu’à un facteur de 100.
- Passer vers le multi-threading, plus efficace que le mono-thread.
D’autres améliorations peuvent encore être faites: faire du jit, utiliser le GPU (numba) ou encore changer d’interpréteur (Pypy)
Mohamed Amine Ben Amira
Références : GitHub de Pierre Rust
Architecture Hexagonale Level 2 : Comment bien écrire ses tests
Vendredi 14h35 - 15h30
Julien Topçu et Jordan Nourry nous ont présenté un retour d’expérience sur le test d’un projet Java au sein de la Société Générale. Ce projet est construit selon une architecture hexagonale (voir ici pour une bonne intro) mais cet aspect n’était pas un point structurant de la conférence, et les outils présentés restent pertinents pour la plupart des projets.

Image extraite de l'article ci-dessus
Les speakers partent du constat que le test d’un microservice est une tâche complexe pour laquelle il n’existe pas encore de méthode concrète reconnue. Il existe cependant des publications théoriques à ce sujet. En particulier, Martin Fowler a présenté une stratégie de testdécrivant différentes phases complémentaires.
Dans cette approche, chaque phase de test a un rôle précis et c’est uniquement le succès de l’ensemble des phases qui donne un niveau de confiance satisfaisant, ce qui peut être représenté par la fameuse pyramide de test.
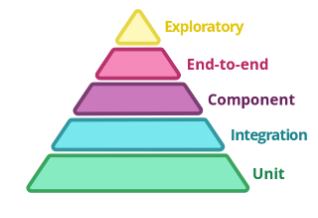
Image extraite de l'article de martin Fowler
Pendant le talk, les speakers ont montré comment l’approche théorique de Martin Fowler a été implémentée dans leur projet. Ils ont en particulier introduit des outils adaptés à chaque phase de test.
Tests fonctionnels
Cette étape vise à vérifier que la couche “domaine” du projet implémente bien les besoins du métier. Pour cela un langage de description “haut-niveau” est très adapté puisqu’il permet aux experts métiers d’écrire des tests dans un langage quasi-naturel. Cucumber et sa syntaxe de type “Given-When-Then” est donc un choix assez évident pour cette phase.
Ces tests sont exécutés en appelant la couche “api” du domaine (au sens de l’architecture hexagonale, pas de l’habituelle API REST de l’architecture 3-tiers) et en bouchonnant la couche “spi” avec des stubs de test. Ils s’exécutent donc rapidement, sans aucune dépendance externe.
Tests unitaires
Pas de surprise au niveau des tests unitaires, le trio JUnit, Mockito et AssertJ a apporté satisfaction. Les speakers ont néanmoins rappelé l’intérêt de la génération de données de test : au lieu de créer des objets de test dans chaque classe de test unitaire, il est souvent plus efficace de mettre en place un service chargé de fournir ces données.
Tests d’intégration
Cette phase de test vise à qualifier les parties “hors-domaine” de l’architecture hexagonale qui communiquent avec des services externes ainsi que les controllers REST. Dans le cas où l’interface publique du projet est une API REST, spring-rest-docs associé à spring-mvc-test permet de valider les controllers Rest tout en générant des exemples de requêtes au format Asciidoc. Ces exemples peuvent ensuite être intégrés facilement dans la documentation de l’API.
Sur la couche “spi”, les tests d’intégration sont exécutés en utilisant les services externes réels. Pour cette raison, ces tests sont fragiles (une perte de connexion réseau peut faire échouer un test) et il est souvent recommandé de ne pas les considérer comme bloquants pendant l’intégration continue.
Tests du composant complet
Dans cette phase, on cherche à montrer que les différentes classes techniques interagissent correctement avec les classes du domaines. Pour cela l’artefact du projet est démarré mais toutes les dépendances externes sont bouchonnées. Pour cela, des bases de données embarquées sont utilisées, ainsi que des frameworks comme Wiremock pour simuler des services tiers. Cette phase de test doit être jouée pendant l’intégration continue et ne nécessite pas le déploiement du composant sur une plate-forme de test.
Dans le cadre d’une architecture micro-service, spring-cloud-contract est très utile pour cette phase de test. En effet, il permet 1/ de définir un contrat via un ensemble de requêtes/réponses, 2/ de vérifier que le serveur respecte ce contrat et 3/ de générer un stub implémentant le contrat. Ce stub peut ensuite être utilisé par les services clients pour faire leurs propres tests.
Tests de bout-en-bout
Une fois l’artefact déployé sur une plate-forme similaire à la plate-forme cible, des tests supplémentaires sont effectués pour vérifier que le composant continue de fonctionner une fois que les bouchons sont remplacés par les services cibles. La définition des tests peut être faite avec un outil comme Karaté. Attention, la principale difficulté de cette phase réside dans l’écriture des critères de succès qui ne doivent pas être trop précis pour que les tests restent maintenables.
Les développeurs Java disposent aujourd’hui d’un riche arsenal d’outils de test, il ne leur reste qu’à définir le périmètre de test pour chaque étape 🙂. Le principal risque est de chercher à tout tester à chaque fois, il faut toujours garder à l’esprit que c’est le succès de l’ensemble des phases qui garantie la qualité du livrable.
Tristan Denmat
À la prochaine !
Et voilà pour notre récapitulatif pour cette mouture 2019 ! Merci aux organisateurs de nous avoir bichonnés encore une fois durant ces trois jours riches d’enseignements (et de bonbons…). On se retrouve l’année prochaine pour une dixième édition (!) qui s’annonce d’ores et déjà légendaire.


