
Sur un projet client récent, on s’est retrouvés face à une API Spring conséquente, le genre qui s’est construite au fil des années, avec des dizaines d’endpoints, des modèles de données entrecroisés, et une documentation… disons, optimiste. Onboarder un nouveau développeur dessus prenait du temps. Comprendre quelles ressources existaient, ce qu’on pouvait interroger, comment les données se reliaient entre elles : ça demandait de fouiller le code, de lire les tests, d’aller chercher le·la bon·ne expert·e.
L’idée qui a germé : et si on exposait cette API comme un serveur MCP ? Pas pour automatiser des tâches, pas (encore) pour construire un agent. Juste pour pouvoir brancher Claude Code dessus et s’en servir comme d’un outil d’exploration. Poser des questions en langage naturel, naviguer les ressources, comprendre les relations entre les entités, avec le LLM comme interface.
Ça a marché. Et la mise en œuvre était plus simple qu’on ne l’anticipait.
Ce qu’est MCP, en deux phrases
Le Model Context Protocol définit un contrat structuré entre un client (un agent, un outil comme Claude Code) et un serveur qui expose des outils : des fonctions nommées, décrites, typées, que le client peut découvrir et appeler. Le protocole sous-jacent est du JSON-RPC sur HTTP ou stdio.
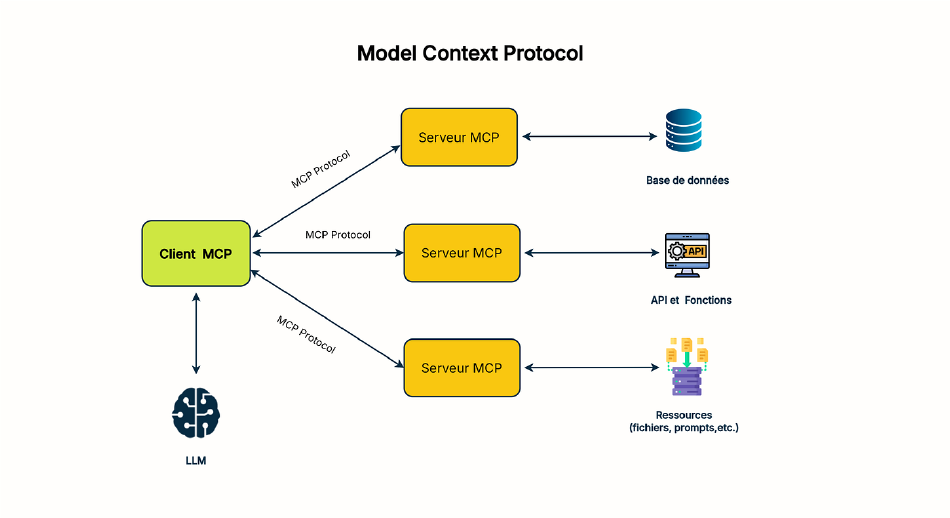
Anthropic a initié la spécification, mais l’écosystème l’a adoptée rapidement : Claude Code, Cursor, Zed et la plupart des frameworks agentiques le supportent nativement. C’est devenu le standard d’interopérabilité entre agents et services.
Partir d’un service Spring existant, sans le réécrire
Pour l’exemple, prenons une bibliothèque numérique classique en Kotlin, plus simple que notre API toufue, mais le principe est identique. Rien d’exotique : un service Spring, un repository JPA, quelques méthodes.
data class Book(
val id: Long? = null,
val title: String,
val author: String,
val isbn: String? = null
)
@Service
class BookService(private val bookRepository: BookRepository) {
fun findAll(): List<Book> = bookRepository.findAll()
fun findById(id: Long): Book =
bookRepository.findById(id).orElseThrow()
fun search(query: String): List<Book> =
bookRepository.findByTitleContainingOrAuthorContaining(query, query)
fun save(title: String, author: String, isbn: String?): Book =
bookRepository.save(Book(title = title, author = author, isbn = isbn))
}
C’est exactement ce qu’on retrouve dans 80 % des applications Spring Boot. La question : comment rendre ce service exploitable par un agent sans tout réécrire ?
Une dépendance
Ajoutez spring-ai-starter-mcp-server-webmvc à vos dépendances (Spring Boot 4.0.5, Spring AI 2.0.0-M4). Le starter embarque l’auto-configuration pour détecter vos outils et démarrer le serveur MCP sur le transport HTTP (streamable HTTP, le successeur du transport SSE désormais déprécié dans la spécification MCP). Côté application.yml, un minimum suffit :
spring:
ai:
mcp:
server:
name: bibliotheque-api
version: 1.0.0
protocol: STREAMABLE
Le reste vient des annotations.
@McpTool en pratique
Reprenons notre BookService et ajoutons deux annotations :
@Service
class BookService(private val bookRepository: BookRepository) {
@McpTool(description = "Recherche des livres par titre ou nom d'auteur dans la bibliothèque")
fun search(
@McpToolParam(description = "Terme de recherche : titre partiel ou nom d'auteur", required = true)
query: String
): List<Book> =
bookRepository.findByTitleContainingOrAuthorContaining(query, query)
@McpTool(description = "Récupère les détails complets d'un livre à partir de son identifiant")
fun findById(
@McpToolParam(description = "Identifiant numérique unique du livre", required = true)
id: Long
): Book? =
bookRepository.findById(id)
@McpTool(description = "Ajoute un nouveau livre dans la bibliothèque")
fun save(
@McpToolParam(description = "Titre complet du livre", required = true)
title: String,
@McpToolParam(description = "Nom complet de l'auteur (Prénom Nom)", required = true)
author: String,
@McpToolParam(description = "ISBN du livre au format ISBN-13, optionnel")
isbn: String?
): Book =
bookRepository.save(Book(title = title, author = author, isbn = isbn))
}
Le delta avec le code original est minimal. Et pourtant, ce service est maintenant un serveur MCP fonctionnel.
Mais regardez bien les descriptions. C’est la partie qui compte.
Quand un agent doit décider quel outil appeler, il ne lit pas votre code : il lit ces chaînes de caractères. Une description vague comme "Cherche un livre" fonctionnera, certes. Mais une description précise comme "Recherche des livres par titre ou nom d'auteur dans la bibliothèque" permet à l’agent de comprendre quand utiliser cet outil et comment formuler ses paramètres. La même logique s’applique aux @McpToolParam : précisez le format attendu, les valeurs possibles, ce qui est optionnel. C’est du contrat, pas de la documentation.
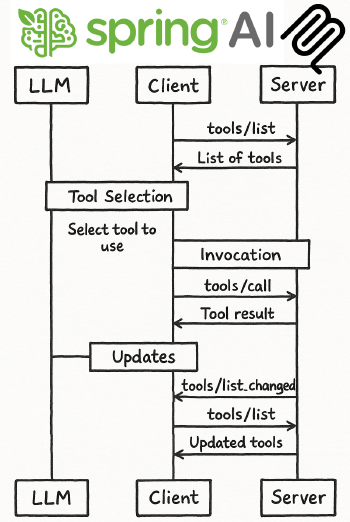
Spring AI génère automatiquement le schéma JSON de chaque outil à partir de ces annotations, et l’enregistre dans le serveur MCP au démarrage. Aucune configuration supplémentaire. L’auto-configuration Spring Boot fait le reste.
Découverte : ce que voit l’agent
Un client MCP peut interroger tools/list pour découvrir ce qui est disponible. Voici ce que renvoie notre serveur :
{
"tools": [
{
"name": "search",
"description": "Recherche des livres par titre ou nom d'auteur dans la bibliothèque",
"inputSchema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "Terme de recherche : titre partiel ou nom d'auteur"
}
},
"required": ["query"]
}
},
{
"name": "findById",
"description": "Récupère les détails complets d'un livre à partir de son identifiant",
"inputSchema": {
"type": "object",
"properties": {
"id": {
"type": "integer",
"description": "Identifiant numérique unique du livre"
}
},
"required": ["id"]
}
},
{
"name": "save",
"description": "Ajoute un nouveau livre dans la bibliothèque",
"inputSchema": {
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "Titre complet du livre"
},
"author": {
"type": "string",
"description": "Nom complet de l'auteur (Prénom Nom)"
},
"isbn": {
"type": "string",
"description": "ISBN du livre au format ISBN-13, optionnel"
}
},
"required": ["title", "author"]
}
}
]
}
C’est le contrat que l’agent utilisera pour orchestrer ses appels. Les data classes Kotlin sont sérialisées automatiquement, les types sont inférés, les champs nullable deviennent des propriétés optionnelles dans le schéma.
Et quid de la sécurité ?
Exposer un serveur MCP, c’est exposer des capacités d’action : pas uniquement de la lecture, potentiellement de l’écriture. Si save() crée des entrées en base, tout client qui peut joindre le serveur peut le faire. Ce n’est pas un problème MCP spécifique, c’est le même risque qu’une API non protégée.
Au niveau du protocole lui-même, la sécurité MCP est encore en mouvement. La spec a d’abord reposé sur de simples API keys, puis migré vers le dynamic client registration OAuth2 — une approche plus robuste, mais qui peut se révéler contraignante selon les contextes. Le sujet est actif : des solutions émergent, comme le projet spring-ai-community/mcp-security ou le travail de Daniel Garnier-Moiroux sur spring-ai-mcp-security (présenté au Devoxx 2026).
En pratique, sécuriser un serveur MCP de façon fine reste un chantier ouvert. C’est à prendre en compte avant tout déploiement partagé.
En action avec Claude Code
Avec le serveur qui tourne en local, connecter Claude Code prend trente secondes. Dans un fichier .mcp.json à la racine du projet :
{
"mcpServers": {
"bibliotheque": {
"type": "http",
"url": "http://localhost:8080/mcp"
}
}
}
Ou via la CLI :
claude mcp add bibliotheque --transport http http://localhost:8080/mcp
Un claude mcp list ou /mcp depuis la CLI confirme que le serveur est référencé. À la session suivante, les outils de la bibliothèque sont disponibles dans le contexte de l’agent : il peut rechercher des livres, consulter leurs détails, en ajouter, sans qu’on lui ait rien expliqué au-delà des descriptions @McpTool.
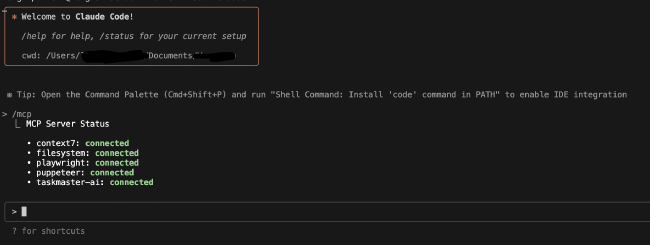
Ce qu’on peut faire concrètement
Maintenant qu’on a vu comment c’est simple à mettre en place, regardons ce que ça débloque concrètement.
Le premier cas, et celui qui nous a convaincus sur le projet client, c’est l’onboarding. Plutôt que de remettre à chaque nouveau·elle arrivant·e un document Word de 40 pages qui sera périmé dans six mois, vous lui donnez accès au serveur MCP dans son Claude Code. Il ou elle peut demander directement : “Quelles ressources expose cette API ?”, “Comment créer une commande ? Quels champs sont obligatoires ?”, “Quelle est la différence entre un Order et un Cart dans ce domaine ?”. Le LLM interroge les outils, compose les réponses, recoupe les informations. C’est une documentation vivante, qui répond aux vraies questions.
Le deuxième cas, plus inattendu : la génération de diagrammes. En combinant votre serveur MCP avec le MCP Draw.io, Claude Code peut interroger vos entités et générer automatiquement des diagrammes de domaine ou des flux de données. Vous demandez “Génère un diagramme des relations entre les entités principales”, il appelle vos outils pour récupérer les structures, puis produit le XML Draw.io directement. Pour une API dont personne n’a jamais pris le temps de dessiner l’architecture, c’est précieux.
Le troisième, plus général, c’est simplement l’exploration. Tester des hypothèses sur les données sans ouvrir Postman, vérifier qu’un identifiant existe, comprendre comment une ressource est structurée en production, sans quitter son contexte de développement. Le serveur MCP devient une fenêtre interactive sur votre système.
Et puis il y a un quatrième cas, plus inattendu, qu’on n’avait pas anticipé : le croisement avec les connaissances du LLM. Quand vous branchez Claude Code sur une API de bibliothèque, il ne fait pas que récupérer vos données : il les croise avec tout ce qu’il sait déjà. Vous pouvez demander “Est-ce que ce livre a gagné le prix Hugo ?” : il appelle votre outil search, récupère le livre depuis votre base, puis mobilise ses propres connaissances sur les prix littéraires pour répondre. Vos données métier d’un côté, la culture générale du modèle de l’autre : les deux se combinent naturellement.
Sur une API de e-commerce, ça pourrait donner “Ce produit est-il adapté pour des enfants de 6 ans ?” sans que vous ayez jamais modélisé une notion d’âge. Sur une API RH, “Ce profil correspond-il aux exigences typiques d’un poste de tech lead ?”. Le MCP vous donne accès à vos données, le LLM apporte le contexte du monde. C’est là que ça devient intéressant.
Ouvrons une parenthèse sur les approches CLI
Il existe une autre façon d’exposer des outils MCP, sans écrire un seul bean Spring : utiliser directement des CLI existants. Des outils comme playwright-cli ou n’importe quel outil en ligne de commande bien documenté peuvent être configurés comme serveurs MCP en décrivant simplement leur aide à l’agent. Pas de code, pas de déploiement, opérationnel en cinq minutes.
C’est pratique pour un prototype ou un usage purement local. Mais c’est aussi là que le bât blesse.
Avec cette approche, vos clés d’API et credentials doivent vivre quelque part accessible au client : fichier de config local, variable d’environnement sur la machine du développeur. Il n’y a pas de couche backend pour les masquer. Si l’agent tourne sur une machine de développement isolée, c’est acceptable. Si vous envisagez un déploiement partagé ou un contexte d’entreprise, vous perdez précisément ce que votre backend Spring vous donnait.
Le serveur MCP Spring reste derrière votre infrastructure. Les credentials, les tokens d’API tiers, les règles métier restent dans le backend, protégés, invisibles du client. Vous conservez un périmètre de sécurité clair, des secrets côté serveur, des règles d’autorisation centralisées. Selon le contexte, le choix mérite d’être fait consciemment.
En résumé
MCP est un contrat d’interopérabilité entre agents et services. Spring AI 2.x permet de l’adopter sur une base de code existante avec un impact minimal : une dépendance et des annotations sur vos méthodes de service. Aucune réécriture.
Ce qui fait réellement la différence, c’est la qualité des métadonnées dans @McpTool et @McpToolParam. Elles sont le seul guide de l’agent pour comprendre et utiliser vos outils correctement. Investissez du temps dans ces descriptions, pas dans la plomberie.
Chez Liksi, on expérimente cette approche sur des projets réels, notamment pour permettre à des agents d’accéder à des services métier sans dupliquer de logique dans des prompts ni exposer des APIs supplémentaires. La migration d’une API Spring existante vers MCP est, en pratique, exactement aussi simple que ce qu’on vient de voir.
Ressources
- Spring AI — MCP Server : https://docs.spring.io/spring-ai/reference/api/mcp/mcp-server-boot-starter-docs.html
- Spring AI — MCP Annotations : https://docs.spring.io/spring-ai/reference/api/mcp/mcp-annotations-server.html
- Model Context Protocol (spec officielle) : https://modelcontextprotocol.io
- MCP — Transports & rétrocompatibilité SSE : https://modelcontextprotocol.io/specification/2025-11-25/basic/transports#backwards-compatibility
- spring-ai-community/mcp-security (expérimental) : https://github.com/spring-ai-community/mcp-security
- Spring AI 2.0 — Upgrade Notes : https://docs.spring.io/spring-ai/reference/upgrade-notes.html
- Claude Code — MCP : https://docs.anthropic.com/fr/docs/claude-code/mcp


